Understanding Encodings
Ezio Melotti
Something about me
- Python Core Developer since June 2009
- Python Programming lecturer at the Turku University of Applied Sciences
- Presented several talks about Unicode and The development process of Python at EuroPython, PyCon FI, PyCon IT
- Member of the Italian Mars Society
As Joel Spolsky said
"If you are a programmer working in 2003 and you don't know the basics of characters, character sets, encodings, and Unicode, and I catch you, I'm going to punish you by making you peel onions for 6 months in a submarine.
I swear I will."
Joel Spolsky, The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
In a submarine...

by mnorri
...peeling onions

by वंपायर
Outline
- Character sets
- Encodings
- Recommendations and common problems
- Q&A
What is a Character Set?
A Character Set is a collection of elements used to represent textual information.
What is a Character Set?
- Most of the Character Sets assign a number to each element - they are also known as Coded Character Sets
ASCII
ASCII
- Limited to 128 chars (7 bits, 2⁷) -- not 256!
- Includes the 26 letters of the English alphabet, the digits 0-9, and a few symbols and control characters
| ASCII | 0x00 to 0x7F |
!"#$%&\'()*+,-./0123456789:;<=>?@
ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`
abcdefghijklmnopqrstuvwxyz{|}~
|
8th bit initially used for parity checking
ASCII
- Limited to 128 chars, English alphabet only
- What about accented letters?
by Tracey Ullom
8th bit then used to represent more characters
ASCII
ASCII
8-bits Character Sets
ASCII, ISO-8859-1
8-bits Character Sets
- 8-bit → 2⁸ → 256 chars: - all the 128 ASCII chars - + 128 more chars, for example:
| ISO-8859-1 (aka Latin1) | 0x00 to 0x7F (ASCII) |
!"#$%&\'()*+,-./0123456789:;<=>?@
ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`
abcdefghijklmnopqrstuvwxyz{|}~
|
| 0x80 to 0xFF | ¡¢£¤¥¦§¨©ª«¬ ¯°±²³´µ¶·¸¹º»¼½¾¿ ÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖ×ØÙÚÛÜÝÞß àáâãäåæçèéêëìíîïðñòóôõö÷øùúûüýþÿ |
- Some accents are still missing, and what about other alphabets?
ISO-8859-* Family
ASCII, ISO-8859-1
ISO-8859-* Family
ASCII, ISO-8859-1, ISO-8859-5
ISO-8859-* Family
ASCII, ISO-8859-1, ISO-8859-5, ISO-8859-5
ISO-8859-* Family
| 1 Western European | 9 Turkish |
| 2 Central European | 10 Nordic |
| 3 South European | 11 Latin/Thai |
| 4 North European | 13 Baltic Rim |
| 5 Latin/Cyrillic | 14 Celtic |
| 6 Latin/Arabic | 15 Western European 2 |
| 7 Latin/Greek | 16 South-Eastern European |
| 8 Latin/Hebrew |
Still not enough...
What if I want to mix русский and العربية?
What if I want to use ᐃᓄᒃᑎᑐᑦ (inuktitut)?!

en.wikipedia.org/wiki/File:IqaluitStop.jpg
{kind=link}
We need a better solution...
ISO-8859-* Family
ASCII, ISO-8859-1, ISO-8859-5, ISO-8859-5
Introducing Unicode
Unicode
Introducing Unicode
Unicode
Introducing Unicode
- Unicode covers all the characters for all the writing systems of the world, modern and ancient.
- Unicode provides a unique number for every character
- no matter what the platform
- no matter what the program
- no matter what the language
- The number is called "codepoint".
- 1114112 different codepoints
- U+0000 to U+10FFFF
- Replaces hundreds of existing character sets
Codepoints
- An integer in the range from 0 to 10FFFF
- Expressed with the notation U+XXXX
- For example 'a' → U+0061, 'ä' → U+00E4
- Each Unicode character (e.g. ☃) has:
- a codepoint (e.g. U+2603)
- a name (e.g. SNOWMAN)
- a category (e.g. So - Symbol, Other)
- a block (e.g. Miscellaneous Symbols)
- and other attributes
Unicode Planes
Unicode is organized in 16 planes, with 65536 codepoints each
- Basic Multilingual Plane (BMP)
- Plane 0: U+0000–U+FFFF
- includes most of the commonly used characters
- Supplementary Planes (non-BMP)
- Plane 1 (U+10000–U+1FFFF): Supplementary Multilingual Plane
- Plane 2 (U+20000–U+2FFFF): Supplementary Ideographic Plane
- Planes 3–13 (U+30000–U+DFFFF): Unassigned
- Plane 14 (U+E0000–U+EFFFF): Supplementary Special-purpose Plane
- Planes 15–16 (U+F0000–10FFFF): Private Use Area
Unicode characters
| Unicode | U+0000 to U+007F (ASCII) |
!"#$%&\'()*+,-./0123456789:;<=>?@
ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`
abcdefghijklmnopqrstuvwxyz{|}~
|
| U+0080 to U+00FF (Latin-1 Supplement) | ¡¢£¤¥¦§¨©ª«¬ ¯°±²³´µ¶·¸¹º»¼½¾¿ ÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖ×ØÙÚÛÜÝÞß àáâãäåæçèéêëìíîïðñòóôõö÷øùúûüýþÿ |
|
| U+0100 to U+017F (Latin Extended-A) | ĀāĂ㥹ĆćĈĉĊċČčĎďĐđĒēĔĕĖėĘęĚěĜĝĞğ ĠġĢģĤĥĦħĨĩĪīĬĭĮįİıIJijĴĵĶķĸĹĺĻļĽľĿ ŀŁłŃńŅņŇňʼnŊŋŌōŎŏŐőŒœŔŕŖŗŘřŚśŜŝŞş ŠšŢţŤťŦŧŨũŪūŬŭŮůŰűŲųŴŵŶŷŸŹźŻżŽž |
|
| U+0180 to U+10FFFF | ... |
How many characters?
512 chars per slide → 2175 slides to represent them all
How many characters?
512 chars per slide → 2175 slides to represent them all

by Ian Albert
Growth of Unicode on the Web (2008)
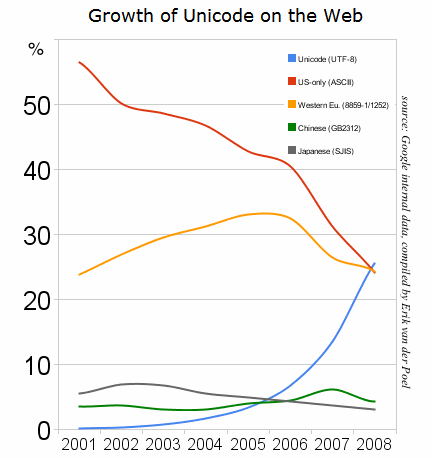
by Google
Growth of Unicode on the Web (2010)
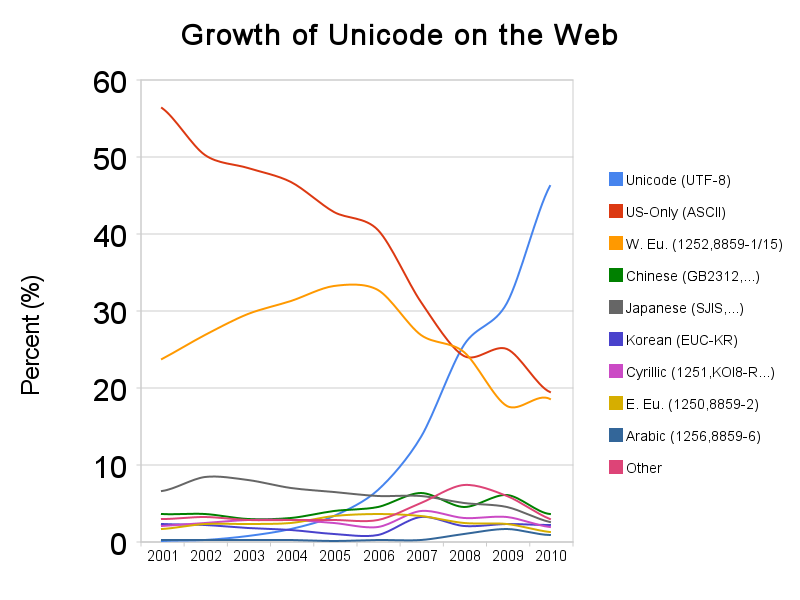
by Google
Growth of Unicode on the Web (2012)
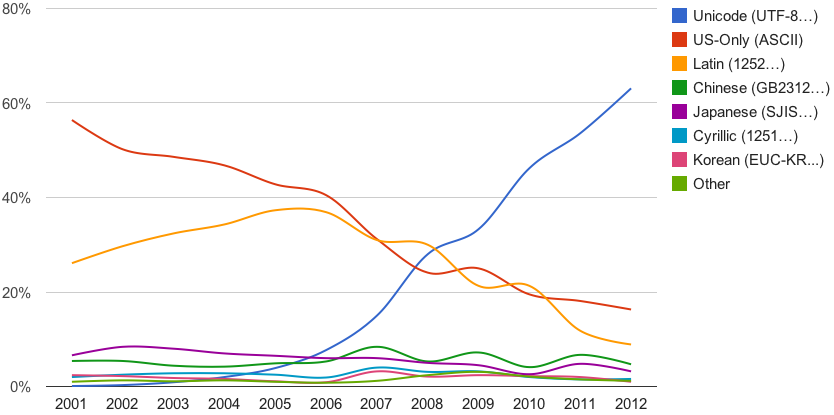
by Google
What is a Character Set?
A Character Set is a collection of elements used to represent textual information.
What is an Encoding?
An Encoding is a mapping from a character set definition to the bit sequences used to represent the data
| Character | Bit sequence | Hex |
|---|---|---|
| 'a' | 0b01100001 | 0x61 |
| 'A' | 0b01000001 | 0x41 |
Encoding/decoding
Encoding: text → bytes
Decoding: bytes → text
Encoding types
Encodings can be divided in:
Single-byte encodings
- Use only 1 byte, limited to 256 characters
Multi-byte encodings
- Use more than 1 byte, and are divided in
- Fixed width: uses a fixed number of bytes for each character
- Variable width: uses a variable number of bytes
8-bits/single-byte Encodings
For 8-bits character sets, the terms "character set" and "encoding" might overlap
- 256 possible chars, 256 values representable with 1 byte (8 bits)
- Single-byte encodings
- For example, ISO-8859-1 is both a character set and an encoding
Cause of endless confusions:
<meta charset="utf-8">
this should actually be called 'encoding'
Unicode Transformation Format (UTF)
UTF family: UTF-8, UTF-16, UTF-32
- can represent all the Unicode codepoint
- multibyte character encodings
- UTF-8 → 1, 2, 3 or 4 bytes
- UTF-16 → 2 or 4 bytes
- UTF-32 → 4 bytes
UTF-8
- always use UTF-8 for your data
- default encoding in lot of places
- if you don't know the encoding, assume UTF-8
UTF-32
UTF-32 is a fixed-width encoding
- each codepoint is encoded with 4 bytes
- not very memory-efficient
- easier to work with (indexing, slicing)
| Character | Codepoint | Bytes (hex) |
|---|---|---|
| 'a' | U+0061 | 00 00 00 61 |
| 'ä' | U+00E4 | 00 00 00 E4 |
| '☃' | U+2603 | 00 00 26 03 |
| '🀩' | U+1F029 | 00 01 F0 29 |
UTF-16
UTF-16 is similar to UTF-32, but uses only 2 bytes
| Character | Codepoint | Bytes (hex) |
|---|---|---|
| 'a' | U+0061 | 00 61 |
| 'ä' | U+00E4 | 00 E4 |
| '☃' | U+2603 | 26 03 |
| '🀩' | U+1F029 | ???? |
but 2-bytes are enough for BMP chars only...
UTF-16 - Surrogates
To represent non-BMP chars, a surrogate pair is used
- two codepoints in range U+D800–U+DFFF combined to obtain a non-BMP char
| Character | Codepoint | Bytes (hex) |
|---|---|---|
| 'a' | U+0061 | 00 61 |
| 'ä' | U+00E4 | 00 E4 |
| '☃' | U+2603 | 26 03 |
| '🀩' | U+1F029 | D8 3C DC 29 |
Surrogates
Surrogates are invalid in UTF-8 and UTF-32
- they can't be encoded/decoded
Surrogates are valid in UTF-16 only if paired correctly
- High-surrogate (U+D800–U+DBFF) + Low-surrogate (U+DC00–U+DFFF)
- Low+High is invalid
- Lone surrogates are invalid
Often they are ignored
- while calculating the len of a string
- while indexing/slicing
- "FFFF codepoints are enough for everyone"
Many things break with surrogates
UTF-8
UTF-8 is variable-width multibyte encoding:
- compatible with ASCII
- 1 to 4 bytes
- 1 byte for ASCII
- 2-3 bytes for BMP chars
- 4 bytes for non-BMP chars
UTF-8 uses
- a start byte
- followed by 0-3 continuation bytes
The start byte specifies how many continuation bytes there will be
UTF-8
| Character | Codepoint | Bytes (hex) |
|---|---|---|
| 'a' | U+0061 | 61 |
| 'ä' | U+00E4 | C3 A4 |
| '☃' | U+2603 | E2 98 83 |
| '🀩' | U+1F029 | F0 9F 80 A9 |
UTF-8
| Bit pattern | Meaning |
|---|---|
| 0xxxxxxx | ASCII byte |
| 10xxxxxx | continuation byte |
| 110xxxxx | start byte of a 2-bytes sequence |
| 1110xxxx | start byte of a 3-bytes sequence |
| 11110xxx | start byte of a 4-bytes sequence |
UTF-8 - decoding example
To find the codepoint, the bytes are converted to binary:
0xE2 0x98 0x83
11100010 10011000 10000011
1110xxxx 10xxxxyy 10yyyyyy
The leading bits used to identify the start of a 2-bytes sequence (1110) and continuation bytes (10) are removed:
----xxxx --xxxxyy --yyyyyy ----0010 --011000 --000011
Divide the 'x' and 'y' bits and convert them to hex:
xxxxxxxx|yyyyyyyy
00100110|00000011
0x26| 0x03
The values are combined to create the codepoint:
U+2603 = ☃
Recommendations
Remember:
- Decode early
- Work with Unicode only
- Encode late
and:
- use always UTF-8 for your data
- never mix text and bytes
- never mix encodings
- never do text processing on bytes
- always know the encoding
Encoding/Decoding - UnicodeErrors
UnicodeError:
UnicodeEncodeError: raised during encoding UnicodeDecodeError: raised during decoding
>>> unistr = 'Minä tykkään Unicodesta!' # Python 3 >>> unistr.encode('ascii') UnicodeEncodeError: 'ascii' codec can't encode character '\xe4' in position 3: ordinal not in range(128) >>> bytestr = unistr.encode('iso-8859-1') >>> bytestr.decode('utf-8') UnicodeDecodeError: 'utf8' codec can't decode bytes in position 3-5: invalid data
Implicit Decoding on Python 2
Python 2 allows to mix Unicode and Byte strings:
>>> u'Unicode and ' + 'Bytes' u'Unicode and Bytes'
- sys.getdefaultencoding() is used
- on Py2 sys.getdefaultencoding() == 'ascii'
- if the 'str' contains non-ASCII chars the decoding fails
>>> u'Unicode and ' + 'ByteSnowMan: ☃' UnicodeDecodeError: 'ascii' codec can't decode byte 0xe2 in position 13: ordinal not in range(128)
Explicit Conversion on Python 3
On Python 3 text and bytes can NOT be mixed:
>>> 'Unicode and ' + b'Bytes'
TypeError: Can't convert 'bytes' object
to str implicitly
Source Encoding
PEP-0263: Defining Python Source Code Encodings
# -*- coding: utf-8 -*- print u'This file is saved in UTF-8 ☺'
Related only to the text in the source file
- not to the encoding that your program will handle
- allows to insert non-ASCII chars in the source code
If not specified, the default is:
- UTF-8 on Python 3 (PEP-3120)
- ASCII on Python 2 (PEP-0263)
Mojibake
Mojibake (文字化け): "unintelligible sequence of characters"
| NOT mojibake | Minä tykkään Unicodesta! |
| UTF-8 showed as ISO-8859-1 | Minä tykkään Unicodesta! |
| ISO-8859-1 showed as UTF-8 | Min� tykk��n Unicodesta! |
- 8-bit encoding can encode/decode everything
- UTF-8 uses '�' in case of errors
Narrow vs Wide
On Python <3.3 there are two different Python builds:
| Narrow | Wide |
|---|---|
| uses UTF-16 internally | uses UTF-32 internally |
| 2 bytes per char | 4 bytes per char |
| sys.maxunicode == 65535 | sys.maxunicode == 1114111 |
| len('🀩') == 2 | len('🀩') == 1 |
| '🀩'[0] == 'ud83c' | '🀩'[0] == '🀩' |
Fixed in Python 3.3! Thanks to PEP 393
PEP 393: Flexible String Representation
- Number of bytes per codepoint determined by the highest codepoint:
- U+0000–U+00FF: 1 byte
- U+0100–U+FFFF: 2 bytes
- U+10000–U+10FFFF: 4 bytes
- Uses less memory
- Still fast (sometimes even faster!)
- Same behavior of wide builds at Python-level
- Backward compatible on the C-level (but you should switch to the new API)
- http://www.python.org/dev/peps/pep-0393/
The end
Questions? ☃